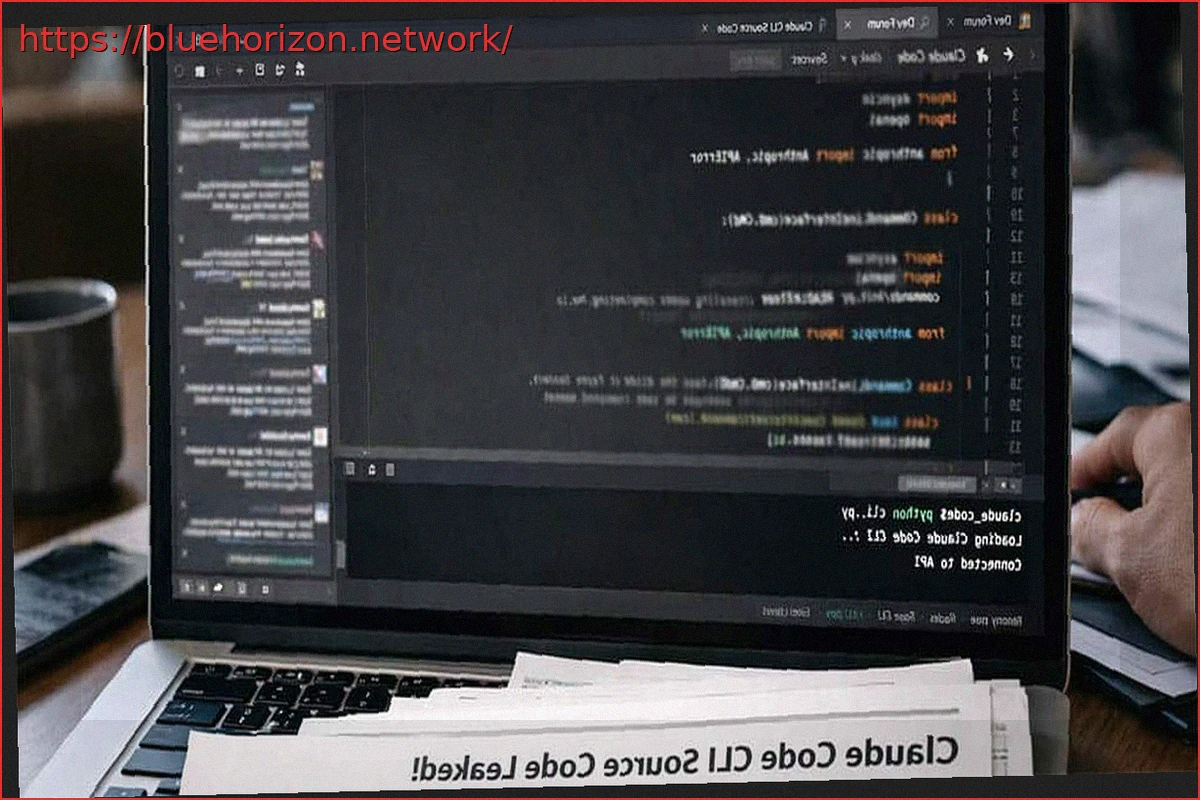
With every new technology, security is a paramount concern. While generative AI has shown susceptibility to trickery like ‘Prompt Injection,’ direct exploits were rare—until now. Researchers have discovered a critical vulnerability in Claude Code’s source code that could allow attackers to steal data from developers.
Preceding modern generative AI, Generative Adversarial Networks (GANs) from 2014-2015 already presented algorithmic security risks.
Claude Code’s First Vulnerability Discovered
Massive language models post-2017 and prompt-based generative AI (since 2022) have faced challenges such as data leaks and ‘Prompt Injection.’ However, a new category of vulnerability has emerged with Claude Code. Researchers from Adversa AI have identified a critical flaw in its permissions system.
The exploit is triggered when processing command chains exceeding 50 subcommands. Claude Code, aiming for performance optimization, bypasses individual checks and executes the entire sequence, opening the door for attackers to steal data.
Anthropic Fixed the Vulnerability in Claude Code Version 2.1.90
An attack scenario could involve a malicious ‘Claude.md’ file in a GitHub repository. Containing over 50 hidden commands, the AI agent would execute all of them without validation from the 51st onwards. This allows the use of commands like ‘curl’ or ‘git’ to exfiltrate sensitive data or cloud credentials from the developer’s local environment to external servers, without their knowledge.
Fortunately, Anthropic has resolved this flaw in version 2.1.90 of Claude Code.