Google has quietly launched DiffusionGemma, an open-source AI model designed to prioritize speed on local GPUs, even at the cost of some quality compared to its predecessor, Gemma 4. This move positions Google within the growing trend of open-source models, particularly those emerging from China like Qwen and DeepSeek, rather than directly competing with high-quality closed models like GPT or Claude.
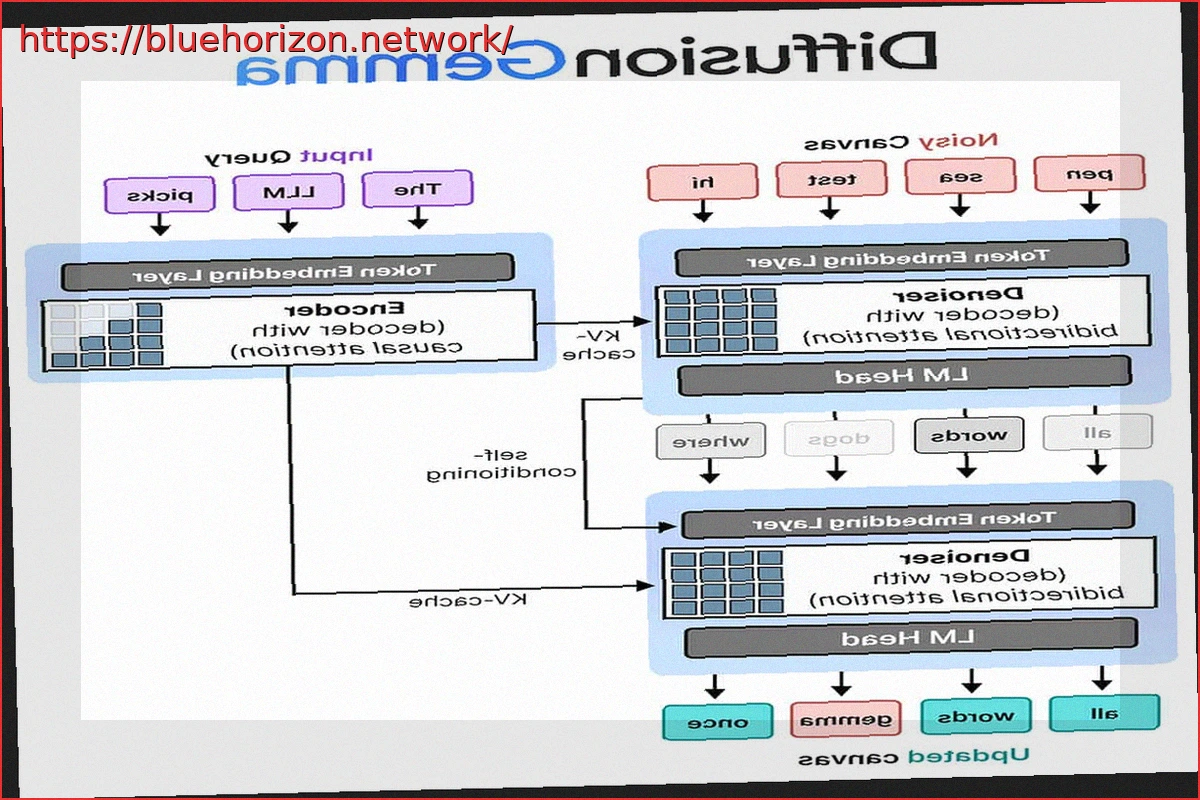
DiffusionGemma’s core innovation lies in its approach to text generation. Instead of token-by-token, left-to-right processing, it generates complete text blocks and then refines them through diffusion. Google highlights this method as ideal for fast, interactive workflows. This fundamental shift promises to significantly alter how local AI operates.
Google DiffusionGemma: The AI That Just Leapt Years Ahead of China
The model builds upon the foundation of Gemma 4 26B A4B, a Mixture-of-Experts (MoE) architecture with 25.2 billion total parameters and 3.8 billion active parameters. This architecture is popular among users and professionals for its ability to manage a large model without engaging its full weight during each inference, which is crucial for local execution on workstations or high-performance consumer GPUs.
Google has also announced support for contexts up to 256K tokens, BF16 format, and NVFP4 quantization, all aimed at reducing memory requirements and accelerating deployments. The diffusion generation process works on a 256-token canvas. Instead of completing responses word by word like GPT or Claude, DiffusionGemma creates a block, reviews and refines it, and then moves to the next. This allows the system to consider the entire block during generation, enabling internal corrections and better utilization of GPU parallel processing capabilities. Google sees this as a significant advantage over traditional autoregressive models, especially those from China, effectively placing them years behind.
Blazing Performance, Better GPU Utilization, Minimal Quality Regression
Google’s performance claims are ambitious: DiffusionGemma promises up to 4x faster speeds on dedicated GPUs, exceeding 1,000 tokens per second on an NVIDIA H100 and over 700 tokens per second on an RTX 5090. It’s also designed for deployment within approximately 18 GB of VRAM with quantization, bringing high-performance local AI within reach of PCs and laptops.
Google acknowledges that Gemma 4’s autoregressive approach remains the preferred choice for maximum quality. Official benchmarks show DiffusionGemma performing below Gemma 4 in tests like MMLU Pro, AIME 2026, LiveCodeBench, GPQA Diamond, vision, and long context. Therefore, DiffusionGemma isn’t positioned to surpass closed frontier models like GPT and Claude, but rather to offer a fast, adjustable, and open-source alternative for PCs, workstations, and laptops. It’s incredibly fast and reliable, though not the absolute best in terms of raw quality.
This nuance aligns DiffusionGemma with the competitive landscape of open-source Chinese AI models. While OpenAI and Anthropic focus on closed, API-based products, the Chinese ecosystem has pushed aggressively with downloadable, competitive open-source models. DiffusionGemma enters this arena with open weights, an Apache 2.0 license, local execution capabilities, and support for text, image, and video processing (as frames). It also supports applications like OCR, document analysis, screen processing, and interactive coding. It’s presented as a disruptive alternative that leverages diffusion for speed, outperforming traditional inference methods.
While Google hasn’t explicitly stated DiffusionGemma is a direct response to China, it directly competes in the space where Chinese open-source models have gained significant traction. The question remains whether this diffusion-based speed will be a technical novelty or the first step towards much faster local assistants, albeit with slightly less fine-tuned outputs than large closed models. The speed at which Chinese companies might replicate this through distillation is also a point of speculation, likely to be swift.