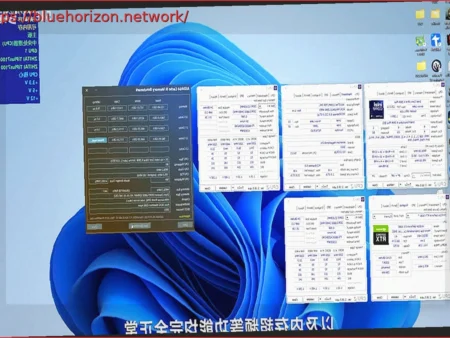
Peter Steinberger, the mind behind OpenClaw and now an OpenAI employee, shared a usage dashboard showing an expenditure of $1,305,088.81 over 30 days. This cost is attributed to 603 billion tokens and 7.6 million requests, reportedly generated by approximately 100 Codex/agent instances used by a team of just three people. This illustrates the true price of having dozens of agents continuously programming, reviewing code, and executing tasks.
The figure is striking not only for its amount but also for what it reveals. AI-assisted development can dramatically increase computational consumption when scaling from occasional chatbot use to deploying a small army of autonomous agents. These agents go beyond answering questions; they review pull requests, scan commits for vulnerabilities, de-duplicate GitHub issues, write fixes, propose new changes, and monitor benchmarks for regressions. It’s even mentioned that some agents can attend meetings and generate summaries of the discussions.
Over $1.3 Million Spent on OpenClaw: Primarily Linked to Fast Mode
OpenClaw is not a simple code assistant but an open-source personal agent project. Its repository describes it as an AI assistant that runs on the user’s devices, responds in existing channels, and can integrate with services like WhatsApp, Telegram, Slack, Discord, Google Chat, Signal, iMessage, Microsoft Teams, Matrix, LINE, WeChat, and many more. The repository currently boasts approximately 372,000 stars and 77,200 forks, helping to explain OpenAI’s interest in hiring Peter.
Peter’s hiring by OpenAI was announced in February. He explained on his blog that he was joining the company to work on agents, while OpenClaw would transition to a foundation and remain open and independent. He also stated that OpenAI was already sponsoring the project and that their goal was to build agents usable by ordinary users, not just technical professionals.
The most significant aspect of the news lies in the economics of the product. Peter clarified that the $1.3 million reflects the use of Fast Mode, a mode that consumes credits at a significantly higher rate. He noted that disabling this mode would have reduced the gross API cost to around $300,000. Even so, this remains a substantial sum for a single project involving three people. This case serves to illustrate the gap between what many users pay through subscriptions and the actual cost of running intensive agents around the clock.
AI Enters a Phase Where the Bottleneck is More Tied to Inference Cost Than Model Quality Itself
Performing some quick math, the expenditure equates to approximately $2.16 per million tokens on average, about 17 cents per request, and around 79,000 tokens per request. If the estimated cost without Fast Mode were considered, the $300,000 would equate to about $0.50 per million tokens and roughly 4 cents per request. The daily average for each of those 100 instances would be about 201 million tokens, 2,533 requests, and approximately $435 per day.
This case comes just after OpenAI shifted its Codex pricing to a model more aligned with actual token consumption. The company indicated that on April 2, 2026, they updated Codex prices to align with API token usage. On April 23, they extended this change to all existing Enterprise plans. The system is now based less on average per-message estimates and more on credits per million input tokens, cached input tokens, and output tokens.
This detail is crucial because programming tasks with agents can be particularly expensive. They not only generate responses but also read repositories, execute reasoning cycles, review errors, re-test changes, and produce lengthy outputs. OpenAI acknowledges that, on average, Codex can cost between $100 and $200 per developer per month. However, they warn of significant variability depending on the model used, the number of instances, the level of automation, and the use of Fast Mode. The case of OpenClaw is thus positioned at the more aggressive extreme of this scale.